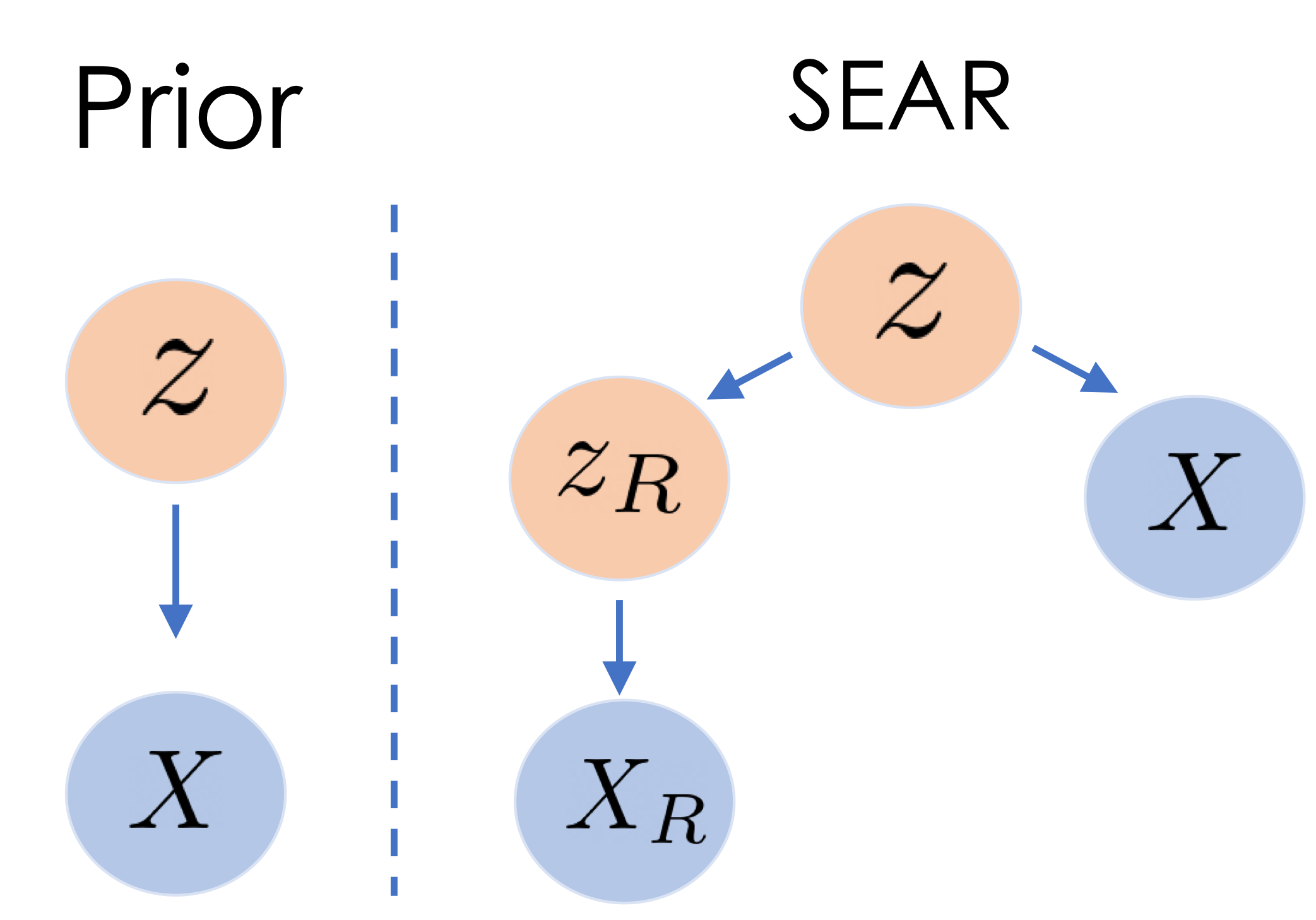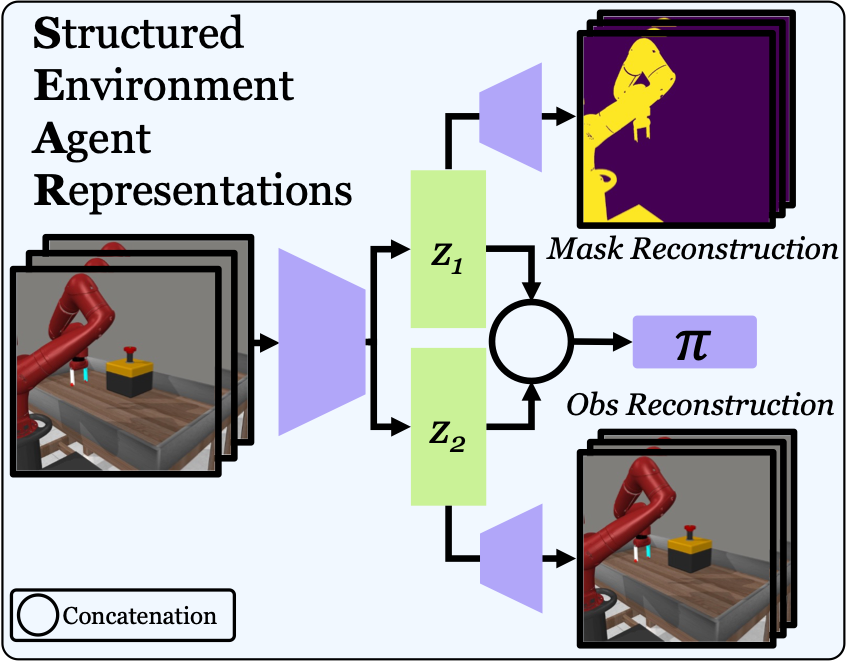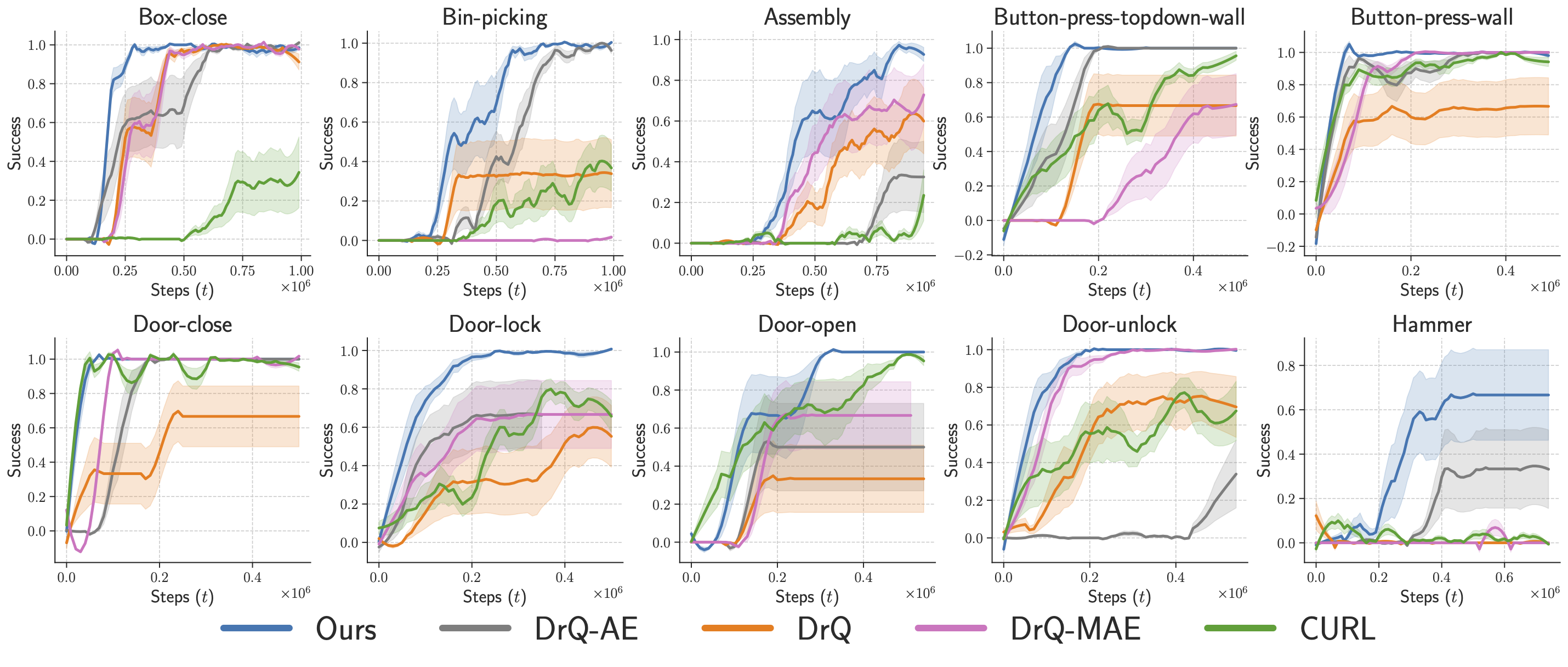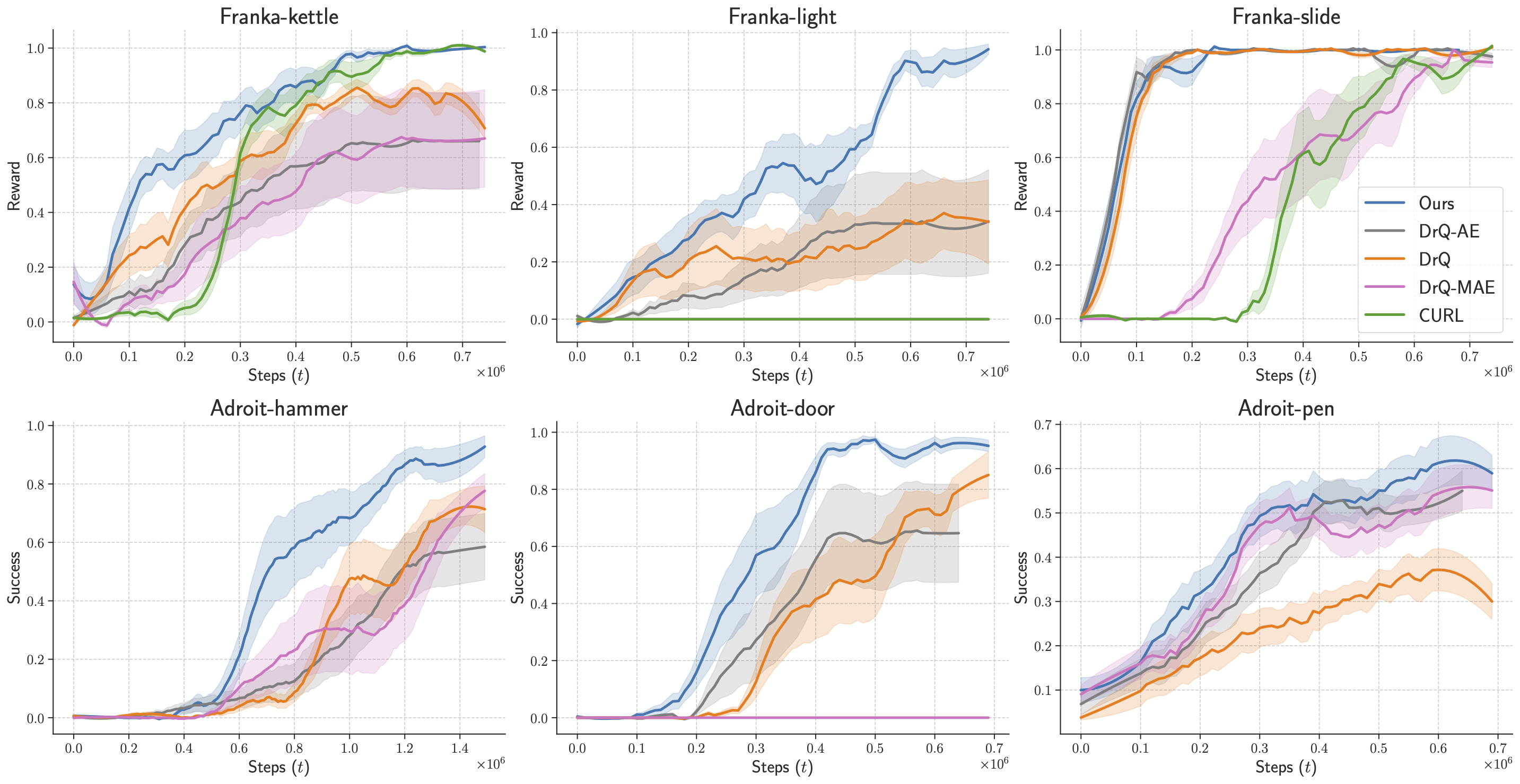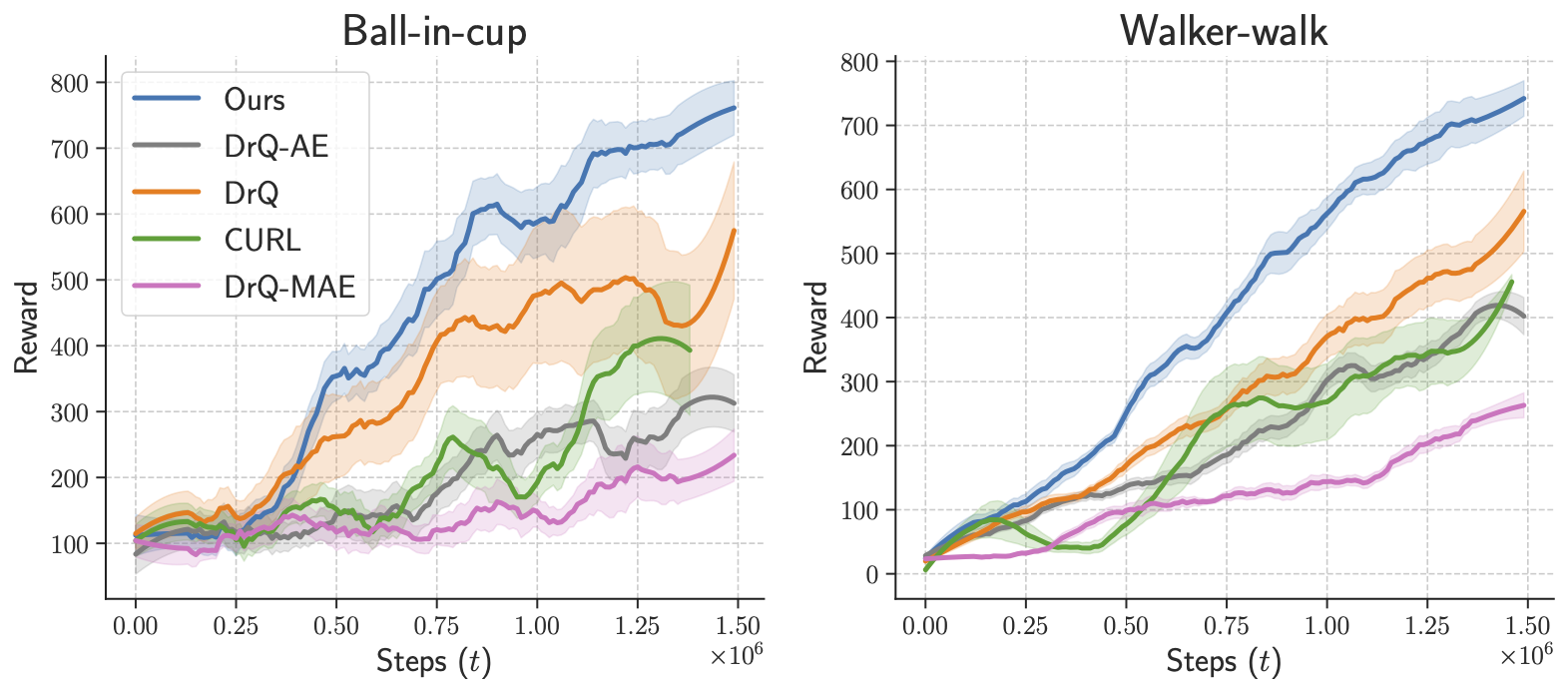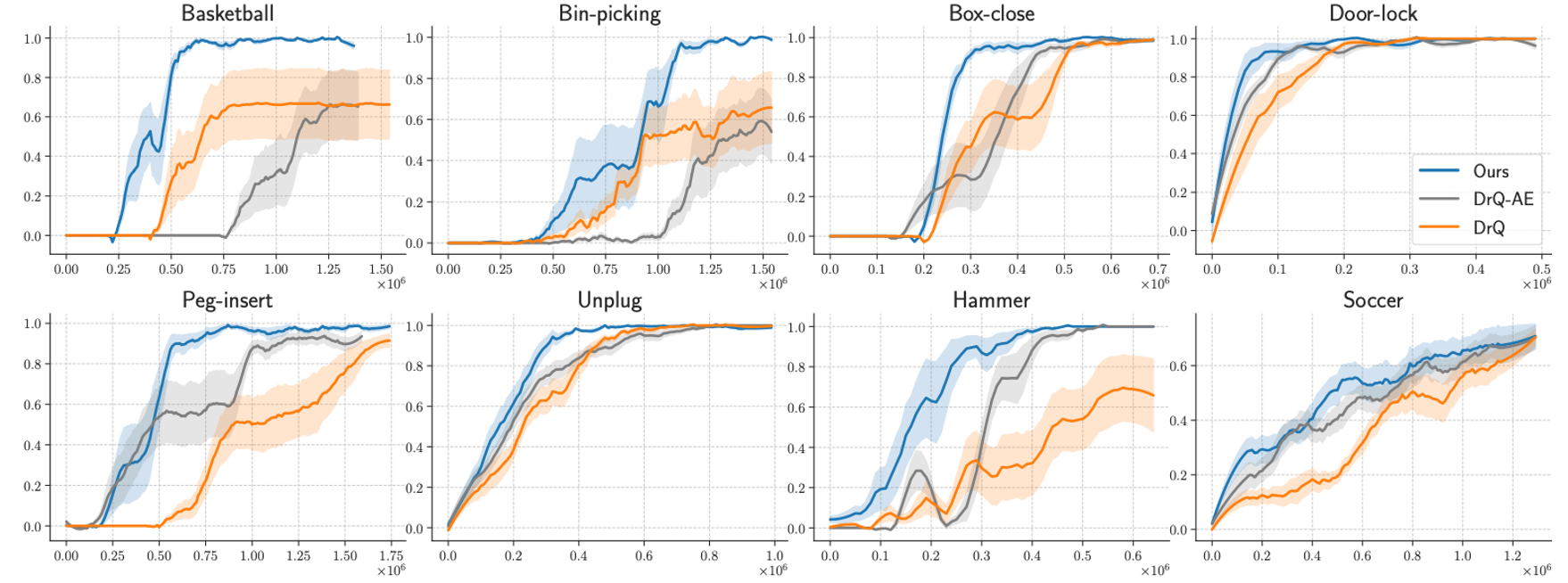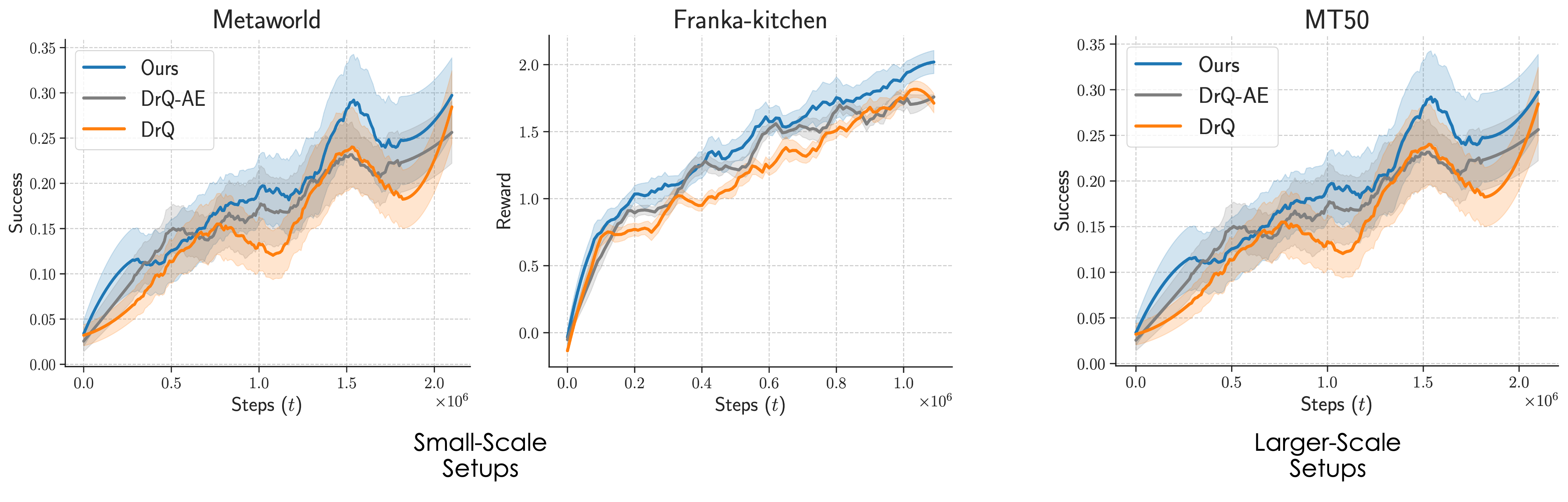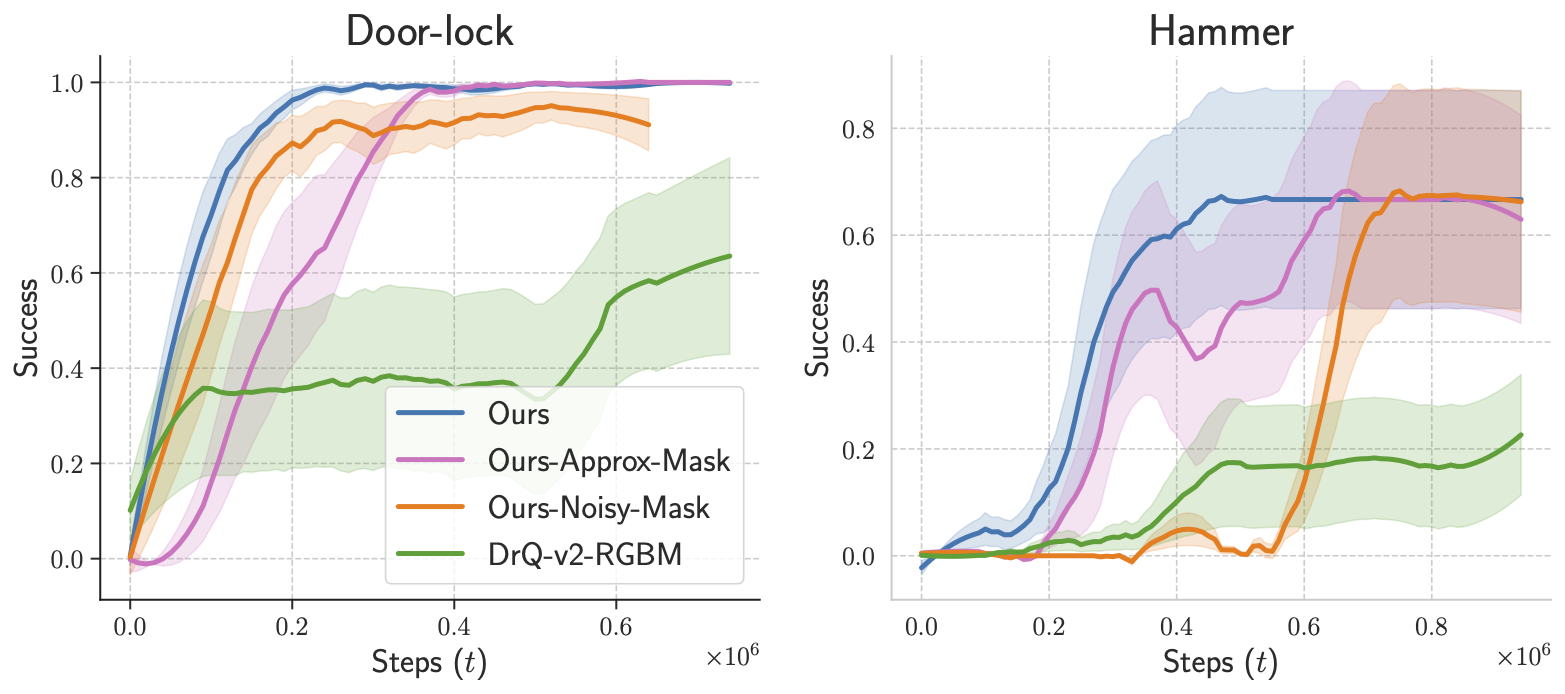
In robotics and AI, the question of how a machine perceives and interacts with its environment is a complex
puzzle. While humans and animals have an innate "sense of self" that allows them to navigate and manipulate
the world efficiently, most robotic systems struggle with this concept. They often require massive amounts of
data to learn even simple tasks, and their adaptability across different environments or tasks is limited.
What if robots could have a more nuanced understanding of themselves in relation to their surroundings? What if they could distinguish between their "inner-self" and the "outer-environment," much like biological entities do? Motivated by these questions, our paper seeks to tackle the following question:
What if robots could have a more nuanced understanding of themselves in relation to their surroundings? What if they could distinguish between their "inner-self" and the "outer-environment," much like biological entities do? Motivated by these questions, our paper seeks to tackle the following question:
Can we learn and leverage the distinction between inner-self and outer-environment to improve visual RL?